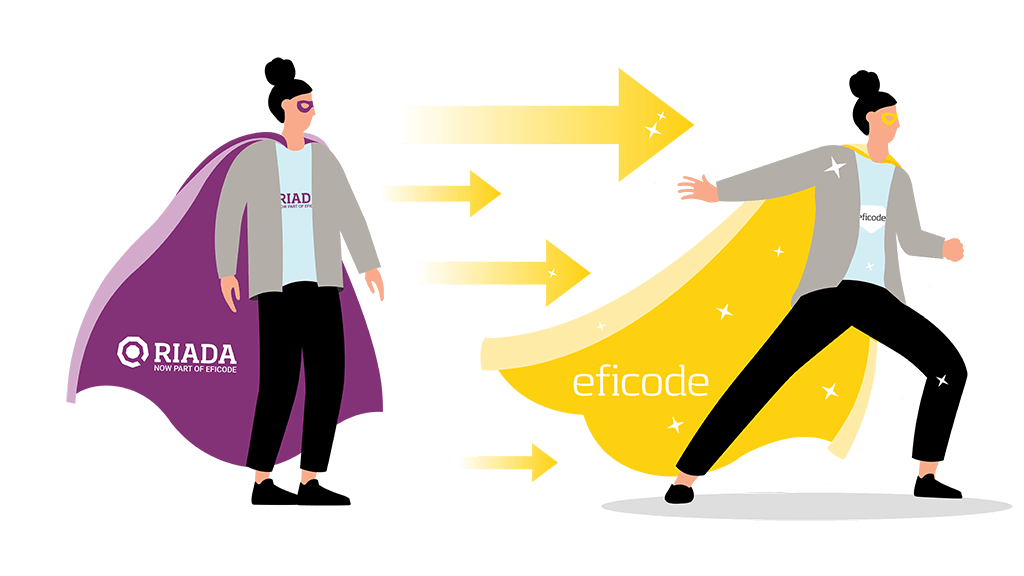
Same people - new cape
Your superheroes from Riada will continue to do their awesome job, but in a brand new Eficode cape. This means you’ll be getting your services from a bigger, even more knowledgeable consultancy. And we are ready to take on the future challenges together with you. We will continue our quest to enhance collaboration in every organization.
We are changing some things
Switching to the yellow cape comes with some changes to what we offer. Here are a few.
.png?width=500&name=unnamed%20(1).png)
500% competence growth
From 60 to 500+ colleagues. Our competence and knowledge has broadened and increased a lot. Get expert consultation at every step.
.png?width=500&name=unnamed%20(3).png)
Empowered hosting services
You will now be able to get services for almost all popular DevOps toolchains and custom applications. Check out Eficode ROOT and Eficode Application Management.
.png?width=500&name=unnamed%20(2).png)
A wider range of trainings
Empower your entire team with new skills. Let us educate your team within Agile, DevOps, Atlassian, Cloud and much more.
Eficode acquires Riada
With the Riada acquisition, Eficode doubles down on the strong growth of the Atlassian software ecosystem and on the adoption of agile and DevOps practices and tools.
Read press release
We do cherish our roots
Some things change and some just don’t. With our new Eficodes capes on, we will continue to challenge and develop our customers and ensure that high quality runs through everything we do. We promise you that this will never change:

Being an Atlassian Partner
We are one of the largest Atlassian Platinum Solution Partner Enterprise in Europe and our award-winning consultants will continue to deliver the best Atlassian solutions for you.

Our culture and values
We will continue to believe in an open, free and inspirational environment where we help you make the impossible possible. Read more.

Our customer promise
Our promise is to enhance collaboration in every organization. We find joy and satisfaction in helping teams reach their goals.
If you are an existing customer...
Our work with you continues as before. We still use the same familiar service desk, and we look forward to hearing from you!

Eficode is a fun family
From the land of a thousand lakes, reindeer, Moomin and saunas - Eficode started as a DevOps services company, but has rapidly established itself as a European leader in Agile and DevOps. Multiple companies have joined together, creating a unique blend of consulting, training and managed services.

DevOps expertise
Get the consulting, training and managed
services you need to do DevOps right.

Cloud capabilities
Harness the full power of cloud.
We can help from end to end.

Agile transformation at enterprise scale
Respond to change quickly and deliver continuously - we’ll support your agile transformation.
We promote learning and teaching
One unique thing about Eficode is the dedication to learning and educating. Keep an eye out for new exciting content. Here are a few examples:


